|
Sie sind hier:
Home >
Lexikon >
Barcode-Lexikon >
Barcode-Typen
Barcode Überblick |
Barcode-Typen |
Barcode Scan-Technologien |
EAN 13 - Ländercodes
Barcode-Typen-Übersicht

| Muster |
Typ |
Beschrieb |
LINEARE
CODES
(1D-Codes) |
|
|
 |
Code 2/5 Industrial
/
Code 2/5 5 Striche
Industrie |
Industrial Two of Five / Code 2/5 5 Striche Industrie
Allgemein:
Numerischer Code, darstellbar 0 - 9.
Dieser Code ist aufgebaut aus 2 breiten und 3 schmalen Strichen
Druckverhältnis V: schmaler Strich : breitem Strich V = 1 : 2 bis 1
: 3
Lücken beinhalten keine Information
Vorteil:
Der Code besteht nur aus Strichen, in den Lücken ist keine
Information. Grosse Drucktoleranz (+/- 15%), deshalb auch mit den
einfachsten Druckverfahren herstellbar.
Nachteil:
Kleine Informationsdichte. z.B. 4,2 mm/Ziffer bei einer Modulbreite X
= 0,3 mm und Verhältnis V = 1 : 3.
|
 |
Code 2/5 Interleaved
(ITF) |
Code ITF (Interleaved Two of Five / Code 2/5 Interleaved)
Allgemein:
Numerischer Code, darstellbar 0 - 9.
Dieser Code ist aufgebaut aus 2 breiten und 3 schmalen Strichen, bzw. 2
breiten und 3 schmalen Lücken
Druckverhältnis V: schmales Element : breitem Element V = 1 : 2 bis 1 : 3
Ist das schmale Element kleiner als 0,5mm, dann gilt schmales Element :
breitem Element V = 1 : 2,25, bis max. V = 1 : 3.
Die erste Ziffer wird dargestellt mit 5 Strichen, die 2. Ziffer mit den
unmittelbar den Strichen der 1. Ziffer folgenden Lücken.
Vorteil:
Hohe Informationsdichte z.B. 2,7 mm/Ziffer bei einer Modulbreite X =
0,3 mm und Verhältnis V = 1 : 3.
Selbstprüfbar
Nachteil:
Alle Lücken tragen Information, deshalb kleinere Toleranz +/- 10%
|
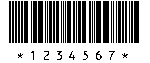 |
Code 39 |
Code 39 Allgemein:
Alphanumerischer Code. Darstellbar 0 - 9, 26
Buchstaben, 7 Sonderzeichen.
Jedes Zeichen besteht aus 9 Elementen (5 Strichen und 4 Lücken).
3 der Elemente sind breit und 6 schmal, mit Ausnahme der Darstellung der
Sonderzeichen. Die Lücke zwischen den Zeichen ist ohne Information
Druckverhältnis V: schmales Element : breitem Element V = 1 : 2 bis 1 : 3
Ist das schmale Element kleiner als 0,5mm, dann gilt schmales Element :
breitem Element V = 1 : 2,25, bis max. V = 1 : 3.
Die erste Ziffer wird dargestellt mit 5 Strichen, die 2. Ziffer mit den
unmittelbar den Strichen der 1. Ziffer folgenden Lücken.
Vorteil:
Alphanumerische Darstellung
Nachteil:
Niedrige Informationsdichte. z.B. 4,8 mm/Ziffer bei einer Modulbreite
X = 0,3 mm und Verhältnis V = 1 : 3
Kleine Toleranz +/- 10%
|
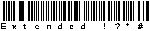 |
Code 39 extended |
|
|
|
Code 93 |
Code 93 |
|
|
Erweiterter Code 93 |
|
 |
Code 128 |
Code 128 Allgemein:
Der Code 128 ermöglicht ohne Zeichenkombinationen den vollen
ASCII-Zeichensatz darzustellen. Jedoch darf nicht angenommen werden, das
der Code 128 mit seinem Zeichensatz alle ASCII-Zeichen direkt darstellen
kann. Es wird zwischen 3 Zeichensätzen A, B und C unterschieden, die je
nach Problemstellung zu verwenden sind. Ebenso ist auch eine
Vermischung dieser Zeichensätze möglich. Um den vollen ASCII-Zeichensatz
darstellen zu können, benötigt man das Startzeichen A oder B in Verbindung
mit einem Sonderzeichen des Code 128. Jedes Zeichen besteht aus 11
Modulen, aufgeteilt in 3 Striche und 3 Lücken. Die Striche bestehen immer
aus einer geradzahligen Anzahl von Modulen (gerade Parität) und die Lücken
aus einer ungeradzahligen Anzahl von Modulen. Das Stopzeichen ist die
Ausnahme und besitzt 13 Module, bestehend aus 11 Modulen und einem
Begrenzungsstrich mit 2 Modulen.
Vorteil:
Voller ASCII-Zeichensatz.
Hohe Informationsdichte
Nachteil:
Kleine Toleranz
Vierbreiten Code
ASCII-Zeichensatz nicht vollständig mit einem Zeichensatz darstellbar
Hinweis:
EAN 128
Entspricht dem Code 128, jedoch wird als Startzeichen die Kombination von
Start A, Start B oder Start C mit dem Zeichen FNC1 verwendet.
|
 |
EAN 8
und
EAN 13
|
EAN Allgemein:
Numerischer Code, darstellbar 0 - 9.
Jedes Zeichen besteht aus 11 Elementen. Alle Striche und Lücken tragen
Information. Es können nur 8 oder 13 Zeichen dargestellt werden.
Siehe auch weitere Details
Vorteil:
Hohe Informationsdichte in 10 verschiedenen Grössen.
Nachteil:
Sehr kleine Toleranzen +/- 10%
|
 |
EAN 128 |
Code EAN 128 Allgemein:
Alle Datenbezeichner und ihre zugehörigen Dateninhalte sind im
Strichcode UCC/EAN 128 (im folgenden nur noch mit EAN 128 bezeichnet)
darzustellen. Als Untermenge des Codes 128 sieht EAN 128 die Verwendung
eines besonderen Zeichens, dem Funktions-Zeichen 1 (FNC 1)*, unmittelbar
nach dem Start-Zeichen vor. Die direkte Hintereinanderfolge von
Start-Zeichen und FNC 1 am Beginn des Strichcodesymbols ist somit
kennzeichnend für den EAN 128. Die Nutzung dieser Zeichenkombination ist
der International Article Numbering Organization, EAN, sowie dem
amerikanischen Uniform Code Council, UCC, vorbehalten.
Für die Bestimmung der maximalen Länge eines EAN
128-Symboles sind drei Parameter ins Kalkül zu ziehen:
- die von der Anzahl zu codierender Zeichen und dem
Vergrösserungsfaktor abhängende physikalische Länge
- die Anzahl der Datenzeichen ohne Hilfszeichen
- die Anzahl der Symbolzeichen
Die Maximallänge eines jeden EAN 128-Symboles muss sich
innerhalb folgender Grenzen bewegen:
- Die physische Länge darf einschliesslich Hellzonen
165 mm nicht überschreiten.
- Inklusive der Datenbezeichner dürfen höchstens 48
Nutzdatenzeichen codiert werden. Sofern FNC1 Zeichen als Trennzeichen
verwendet werden sind sie wie Nutzdatenzeichen zu zählen. Im übrigen
bleiben Hilfs- und Symbolprüfzeichen hier unberücksichtigt.
Inklusive aller Hilfszeichen und des Symbolprüfzeichens
sollte ein EAN 128-Strichcodesymbol 35 Symbolzeichen nicht überschreiten.
Andernfalls besteht die Gefahr, dass ein für betriebsübergreifende
Anwendung nicht ausreichender Vergrösserungsfaktor gewählt werden muss.
Es ist ferner zu beachten, dass bei Verwendung des
Zeichensatzes C die Anzahl der Nutzdatenzeichen die Zahl der dafür
benötigten Symbolzeichen übersteigen kann.
Abgrenzung von Datenelementen fester bzw. variabler
Länge
Datenbezeichner identifizieren Datenelemente mit
variabel oder fest definierter Länge. Wenn mehrere Datenbezeichner und die
dazugehörigen Dateninhalte in einem Symbol verkettet werden, muss jedem
variabel definierten Datenelement ein FNC 1-Zeichen folgen, sofern es sich
nicht um das letzte im Symbol verschlüsselte Datenelement handelt. Bei
Dateninhalten fixer Länge wird ein Trennzeichen nicht benötigt.
Um die Länge eines Datenelementes mit festgelegter
Stellenzahl nach dem Leseprozess ermitteln zu können, ist die Tabelle mit
vordefinierten Längenindikatoren erstellt worden. Einige der hierin
wiedergegebenen Indikatoren werden heute bereits als einzeln stehende
Datenbezeichner genutzt (z.B. "00", "01") bzw. sind in eine Mehrzahl von
Datenzeichnern eingeflossen (z.B. "31", "41").
| Längenindikator |
Länge des
Datenelementes |
| 00 |
20 |
| 01 |
16 |
| 02 |
16 |
| 03 |
16 |
| 04 |
18 |
| 11 |
8 |
| 12 |
8 |
| 13 |
8 |
| 14 |
8 |
| 15 |
8 |
| 16 |
8 |
| 17 |
8 |
| 18 |
8 |
| 19 |
8 |
| 20 |
4 |
| 31 |
10 |
| 32 |
10 |
| 33 |
10 |
| 34 |
10 |
| 35 |
10 |
| 36 |
10 |
| 41 |
16 |
Alle hier nicht aufgeführten Elemente
müssen am Ende ein FNC 1 oder das Stop haben
Es gibt keine saubere Separierung mit FNC 1 zur Abgrenzung neuer
Datenelemente
Die Tabelle legt die Gesamtlänge des Datenelementes, das
sich aus Datenbezeichner und Dateninhalt zusammensetzt, fest. Damit wird
jedoch noch keine Aussage über die Stellenzahl des Datenbezeichners oder
das Format (numerisch oder alphanumerisch) des Dateninhalts gemacht.
Die Tabelle ist zukunftsgerichtet und beständig. Sollten
künftig weitere Datenelemente mit fest definierter Länge in den Standard
aufgenommen werden, so wird für die Wahl des Datenbezeichners auf diese
Tabelle zurückgegriffen. Dadurch kann Verarbeitungssoftware unabhängig von
der Verabschiedung weiterer fest definierter Datenelemente entwickelt
werden. Diese Tabelle ist in jedem Fall in der Verarbeitungssoftware zu
implementieren, da eine Zerlegbarkeit des gelesenen Datenstrings in die
einzelnen Datenelemente andernfalls nicht sicher gewährleistet ist.
Dateninhalte
Die auf einem Datenbezeichner folgenden Dateninhalte
sind, der jeweiligen Anwendungsbeschreibung entsprechend, numerisch oder
alphanumerisch definiert und bis zu 30 Stellen lang.
Die zur Einstellung der Dateninhalte vorgesehene Länge
der Datenfelder ist fix oder variabel definiert. Bei Datenfeldern fixer
Länge ist stets die geforderte Zahl von Zeichen (Ziffern und/oder
Buchstaben) einzustellen. Gegebenenfalls ist ein Datenfeld linksbündig mit
Nullen aufzufüllen, um die geforderte Stellenzahl zu erreichen. Für
variabel definierte Datenfelder ist eine Höchstzahl einstellbarer Zeichen
definiert. Dieses Maximum darf auf keinen Fall überschritten werden.
Beispiel:
3100 Nettogewicht in kg ohne Nachkommastelle
3102 Nettogewicht in kg mit zwei Nachkommastellen
Anmerkung
Als Mengenangabe für eine mengenvariable Handelseinheit
darf ausschliesslich einer der speziell hierfür bereitgestellten
Datenbezeichner (30 und 3100 bis 3169) verwendet werden. Durch diese
Regelung wird eine eindeutige Relation zwischen EAN des Artikels und
Mengenangabe sichergestellt und eine Verwechslung mit anderen
Mengenangaben (z.B. für logistische Zwecke) ausgeschlossen. Für letztere
stehen die Datenbezeichner 3300 bis 3369, 340 und 37 zur Verfügung.
|


|
UPC Version A
und
UPC Version
E
|
Code UPC-A
Code UPC-E
|
 |
Codabar |
Codabar Allgemein:
Numerischer Code mit 6 zusätzlichen
Sonderzeichen. Darstellbar 0 - 9, -, $, ;, /, +
Jedes Zeichen besteht aus 7 Elementen (4 Strichen und 3 Lücken). Dabei,
werden entweder 2 oder 3 breite und 4 oder 5 schmale Elemente zur
Darstellung der Codes verwendet. Die Lücken zwischen den Zeichen tragen
keine Information.
Druckverhältnis V: schmales Element : breitem Element V = 1 : 2,25 max. V
= 1 : 3.
Die erste Ziffer wird dargestellt mit 5 Strichen, die 2. Ziffer mit den
unmittelbar den Strichen der 1. Ziffer folgenden Lücken.
Vorteil:
Ausser 0 - 9 lassen sich noch 6 Sonderzeichen darstellen.
Keine Information in der Lücke zwischen den Zeichen.
Nachteil:
Niedrige Informationsdichte. z.B. 5,5 mm/Ziffer bei einer Modulbreite
X = 0,3 mm und Verhältnis V = 1:3
|
STAPEL
-
CODES
(2d-Codes) |
|
|
 |
Code 49 |
Code 49 Allgemein:
Code 49 ist eine Variante der gestapelten
Strichcodes basierend auf einer eigenen Codestruktur. Die Zeilenanzahl
kann von 2 bis 8 Zeilen variieren. Jede Zeile besteht aus insgesamt 70
Modulen, einem Startzeichen (2 Module), 4 Datenwörtern (4x16 Module) und
einem Stopzeichen (4 Module). Durch die Darstellung der einzelnen
Datenwörter in fest definierten Datenwortkombinationen lassen sich während
dem Lesevorgang die Zeilennummern ermitteln. Es können maximal 49
ASCII-Zeichen oder 81 Ziffern verschlüsselt werden.
Vorteil:
- Kompakter Code
- Flexibilität in der Anpassung von Information auf eine gegebene Fläche
durch variable Höhe und Informationsdichte
- Es können alle herkömmlichen Lesegeräte verwendet werden. Der Dekoder
muss jedoch erweitert werden, da sich Code 49 auf eine eigene
Strichcodierung stützt. Der Dekoder muss aber den gesamten Block des Codes
erfassen bevor der Inhalt an ein übergeordnetes System übertragen werden
kann.
Nachteil:
- Festes Format
- Gestapelte Struktur muss beim Lesen beachtet werden |
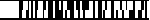 |
Code 16K |
Code 16K Allgemein:
Code 16K ist eine Variante der gestapelten
Strichcodes basierend auf den Elementes des UPC und des Code 128. Es
können 77 ASCII-Zeichen oder 154 Ziffern auf einer Fläche von 2,4 cm²
dargestellt werden. Die Zeilenanzahl kann von 2 bis 16 Zeilen variieren.
Jede Zeile wird indirekt über die Darstellung des Start-/Stopzeichens
erkannt. Die Datensicherheit wird mittels zwei fehlerkorrigierenden
Prüfzeichen gewährleistet. Die Berechnung erfolgt auf der Basis Modulo
107.
Vorteil:
- Sehr kompakter Code
- Flexibilität in der Anpassung von Information auf eine gegebene Fläche
durch variable Höhe, Breite und Informationsdichte
- Es können alle herkömmlichen Lesegeräte verwendet werden. Nur der
Dekoder muss geringfügig erweitert werden, da sich Code 16K auf bereits
bestehende Strichcodierung stützt. Der Dekoder muss aber den gesamten
Block des Codes erfassen bevor der Inhalt an eine übergeordnetes System
übertragen werden kann.
Nachteil:
- Gestapelte Struktur muss beim Lesen beachtet werden |
 |
Codablock (A, F, 256) |
Codablock Allgemein:
Codablock ist als gestapelte Variante zu den
Standard-Strichcodes Code 39 und Code 128 entwickelt worden, um den
Datenzusammenhang einer Nachricht zu erhalten, wenn die Etikettenbreite
nicht ausreicht und mehrere kürzere Strichcodes gedruckt werden müssen.
Jede Zeile enthält einen Zeilenindikator zu Orientierung für das Lesegerät
und zwei Prüfzeichen um den Inhalt der Gesamtnachricht abzusichern. Es
wird in drei Codablockvarianten unterschieden.
Codablock A: Basierend auf der Struktur von Code
39 können bis 22 Zeilen, zu je 1 bis 61 Daten (max. 1'340) generiert
werden. Das Prüfzeichen über die Gesamtnachricht errechnet sich nach
Modulo 43
Codablock F: Basierend auf der Struktur von Code
128 können 2 bis 44 Zeilen, zu je 4 bis 62 Daten (max. 2'725) generiert
werden.
Codablock 256: Diese Variante ist wie Codablock F
aufgebaut, jedoch mit einem eigenen Start-/Stopzeichen. Es können 2 bis 44
Zeilen, zu je 2 bis 62 Daten (max. 2'725) generiert werden. Jede Zeile
verfügt über eine eigene Fehlerkorrektur, so dass kleine Beschädigungen
wieder rekonstruiert werden können.
Vorteil:
- Erhöhte Datensicherheit eines Codablock Etiketts im Vergleich zum
Lesen verschiedener Einzeletiketten zu einer Gesamtnachricht
- Flexibilität in der Anpassung von Information auf eine gegebene Fläche
durch variable Höhe, Breite und Informationsdichte
- Es können alle herkömmlichen Lesegeräte verwendet werden, da sich
Codablock auf bereits bestehende Strichcodierung stützt.
- Das Zusammensetzen der einzelnen Zeilen zur Gesamtnachricht kann auch in
übergeordneten Rechnersystem folgen
Nachteil:
- Gestapelte Struktur muss beim Lesen beachtet werden |
 |
IPC-2D |
|
 |
Supercode |
|
 |
PDF 417 |
PDF 417 Allgemein:
PDF 417 ist eine Variante der gestapelten
Strichcodes basierend auf einer eigenen Codestruktur. Die Zeichen sind in
sogenannten "Codewörtern" verschlüsselt. Jedes Codewort besteht aus 17
Modulen aufgeteilt in 4 Striche und 4 Lücken. Es können bis zu 1'108 Bytes
verschlüsselt werden. Die Zeilenanzahl kann von 3 bis 90 Zeilen variieren.
Jede Zeile enthält einen Zeilenindikator zu Orientierung für das
Lesegerät. Zwei Codewörter dienen als Prüfzeichen, um den Inhalt der
Gesamtnachricht abzusichern. Zur Fehlerkorrektur können weitere Codewörter
(bis zu 512) eingefügt werden. Dies spiegelt sich auch in den
verschiedenen Fehlerkorrekturstufen wider.
Vorteil:
- Sehr kompakter Code
- Flexibilität in der Anpassung von Information auf eine gegebene Fläche
durch variable Höhe, Breite und Informationsdichte
- Es können alle herkömmlichen Lesegeräte verwendet werden. Nur der
Dekoder muss individuell erweitert werden, da sich PDF 417 auf eine
eigene, sehr komplexe Codestruktur stützt. Der Dekoder muss aber den
gesamten Block des Codes erfassen bevor der Inhalt an eine übergeordnetes
System übertragen werden kann.
Nachteil:
- Gestapelte Struktur muss beim Lesen beachtet werden |
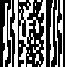 |
Micro PDF |
|
 |
Color Ultra Code |
|
 |
Ultra
Code |
|
|
COMPOSITE CODES |
 |
(Kombination von
Linear- und Stapelcodes) |
 |
RSS-14 Code |
RSS-14 Allgemein:
Der RSS-14 bildet die Grundstruktur für das erweiterte UCC/EAN System.
Es kann mit dem RSS-14 ein Applikationsidentifier "01" und eine
14-stellige Artikelnummer codiert werden. Alle RSS-14 Codes verfügen über
ein Verknüpfungsflag. Ist das Flag auf 1 gesetzt so handelt es sich um
einen Composite Code. In diesem Moment müssen 2 Codes gelesen werden. Der
RSS-14 besteht aus 94 Modulen, aufgeteilt in 46 Elemente. Die Codeworte
bestehen aus 15 bzw. 16 Modulen und werden mit 4 Lücken und 4 Strichen
dargestellt. Das Suchmuster weist 14 Module auf. Die Darstellung der
Striche und Lücken erfolgt über 8 verschiedene Modulbreiten, d.h. die
Elemente können 1X bis 8X breit sein.
Vorteil:
- flexible Codestruktur
- kompakt und sicher aufgebaut
Der Code kann mit 4 Segmentlesungen rekonstruiert werden.
|
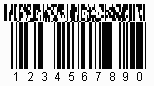 |
RSS-14 mit 2D-Komponente |
Dieser RSS-14 besitzt noch eine 2D-Komponenete, d.h.
das Composite Flag ist gesetzt |
 |
RSS-14 Truncated |
Der RSS-14 Truncated bildet die Basis zur Codierung
kleiner Produkte. Ansonsten ist diese Variante identisch zum RSS-14,
jedoch mit reduzierter Codehöhe und deshalb nicht mehr omnidirektional
lesbar. |
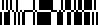 |
RSS-14 Stacked |
Der RSS-14 Stacked bildet mit dem RSS-14 Truncated und
dem RSS-14 Limited eine weitere Variante, um kleine Produkte zu
kennzeichnen.
Identisch zum RSS-14 hinsichtlich der Codestruktur. Durch die reduzierte
Codehöhe und der Stapelform nicht mehr omnidirektional lesbar. |
 |
RSS-14 Stacked omnidirektional |
Identisch zum RSS-14 hinsichtlich der Codestruktur.
Durch Beibehaltung der Codehöhe in der Verbindung mit der Stapelform auch
omnidirektional lesbar. |
 |
RSS-14 Limited |
Der RSS-14 Limited besteht aus 74 Modulen, aufgeteilt
in 46 Elemente. Die Codeworte bestehen aus 26 Modulen und werden mit 7
Lücken und 7 Strichen dargestellt. Das Suchmuster weist 18 Module auf. Die
Darstellung der Striche und Lücken erfolgt über 8 verschiedene
Modulbreiten, d.h. die Elemente können 1X bis 8X breit sein. Nicht
omnidirektional lesbar und kein Applikationsidentifier.
Anwendungen: Handel und Industrie (Elektronikbauteile /
Medikamente) |
 |
RSS-14 Expanded |
Der RSS-14 Expanded ist die variabelste Variante der
RSS-14 Familie. Der Code besitzt minimal 4 und maximal 22 Codeworte, die
zur Codierung von Daten, Zusatzinformationen und einer Prüfziffer dienen.
Die Codeworte bestehen aus 17 Modulen und werden mit 4 Lücken und 4
Strichen dargestellt. Die Suchmuster weisen 15 Module auf, die sich in 3
Lücken und 2 Striche aufteilen. Die Darstellung der Striche und Lücken
erfolgt über 8 verschiedene Modulbreiten, d.h. die Elemente können 1X bis
8X breit sein. Der RSS-14 Expanded ist omnidirektional lesbar. Der Code
ist sehr kompakt uns sicher aufgebaut. Benötigt wenig Platz, da kein
unnötiger Überhang im Code enthalten ist. Der Code kann je nach Länge mit
mehreren Segmentlesungen rekonstiruiert werden.
Numersich: max. 74 Ziffern
Alphanumersich: max. 41 Zeichen
|
 |
RSS-14 Expanded Stacked |
Identisch zum RSS-14 Expanded hinsichtlich der
Codestruktur und ist voll omnidirektional lesbar.
Numerisch: max. 74 Ziffern
Alphanumersich: max. 41 Zeichen |
 |
RSS Limited®
Composite Symbol |
|
 |
RSS-14®
Stacked Composite |
|
MATRIX - CODES
(2D-CODES) |
|
|
 |
Array Tag |
|
 |
Aztec |
|
 |
Code One
und
Code One S |
|
 |
CP Code |
|
 |
Data Matrix |
Data Matrix Allgemein:
Data Matrix ist eine Variante der Matrixcodes und existiert in zwei
Versionen. ECC 000-140 und ECC 200. ECC 200 ist die aktuelle Überarbeitung
und ist empfohlener Weise zu verwenden. Data Matrix besitzt eine variable,
rechteckige Grösse in Form einer Matrix. Die Matrix besteht minimal aus
einer quadratischen Anordnung von 10x10 Symbolelementen und maximal aus
144x144 Symbolelementen. Darüber hinaus ist eine rechteckige Darstellung
von 8x18 und 16x48 Symbolelementen möglich. Es können 2'334 ASCII-Zeichen
(7 Bit) oder 1'558 der erweiterten ASCII-Zeichen (8 Bit) oder 3'116
Ziffern in der Maximalgrösse verschlüsselt werden. Eine waagrechte und
eine senkrechte Umrandung beschreiben eine Ecke, die als
Orientierung für die Lesung dient. An den Gegenüberliegenden Seiten muss
sich die jeweilige Seite mit hellen und dunklen Quadratelementen
abwechseln um die Position und die Grösse der Matrixstruktur zu
beschreiben. Die Informationsdichte beträgt 13 Zeichen pro 100mm²
Vorteil:
- Sehr kompakter Code
- Sehr sicher, da ein mächtiger Fehlerkorrekturalgorithmus, Reed Solomon,
eingebaut ist.
- Rekonstruktion des Dateninhaltes, auch bei einer Beschädigung des
Gesamtcodes bis zu 25% bei dem kleinsten Überhang an
Fehlerkorrekturzeichen
Nachteil:
- Nur mit Bildverarbeitungssystemen lesbar (Image Reader / 2D
Scannern) |
 |
DataStrip |
|
 |
Dot Code A |
|
 |
MaxiCode |
Maxi Code Allgemein:
MaxiCode ist eine Variante der Matrix Codes. Er besitzt eine feste
Grösse von 25,4mm x 25,4mm. Es können 144 Symbol-Zeichen in einer Fläche
von 645mm² dargestellt werden. Maximal 93 ASCII-Zeichen
oder 138 Ziffern. In der Mitte des 2D-Codes befindet sich ein Suchmuster,
bestehend aus 3 zentrischen Kreisen, das als Orientierung für die Lesung
dient. Um dieses Suchmuster herum sind die 866 Sechsecke wabenförmig, in
33 Reihen angeordnet, die den Dateninhalt tragen. Jede der 33 Reihen
besteht aus maximal 30 Wabenelemente. 6 Orientierungswaben zu je 3
Wabenelemente, sind um das Suchmuster im Abstand von 60 Grad angeordnet
und dienen der Lageerkennung für die omnidirektionale Lesung. Die
Informationsdichte beträgt 13 Zeichen pro 100mm²
Vorteil:
- Sehr kompakter Code
- Sehr sicher, da ein mächtiger Fehlerkorrekturalgorithmus eingebaut ist.
- Rekonstruktion des Dateninhaltes, auch bei einer Beschädigung des
Gesamtcodes bis zu 25%
- Omnidirektionale Lesbarkeit auch bei hohen Transportgeschwindigkeiten.
Nachteil:
- Feste Paramter
- Nur mit Bildverarbeitungssystemen lesbar (Image Reader / 2D Scannern) |
 |
QR Code |
|
 |
MiniCode |
|
 |
SmartCode |
|
 |
Snowflake
Code |
|
 |
AccuCode
(3-DI) |
|
 |
Vericode |
|
top
Diese Liste an Strichcode Symbologien ist nicht komplett, aber
über 90% wird damit abgedeckt.
-
Quellenangabe:
-
Strichcode - Fibel, Datalogic
-
2D-Codes, Handbuch der automatischen Identifikation, Band 2;
Bernhard Lenk
|